위의 링크 번역
TensorFlow.js를 사용하여 브라우저에서 실시간 인간 자세 추정하기
Google Creative Lab과 협업하여, PoseNet의 TensorFlow.js 버전 릴리즈을 알리게되어 흥분된다. 이 머신 러닝 모델은 브라우저에서 실시간 인간 자세 추정을 가능하게 한다.
그래서 자세 추정(pose estimation)이 뭔데? 자세 추정은 컴퓨터 비전분야에서 비디오나 이미지의 사람 모양을 탐지하는 것을 나타낸다. 예를들어 누군가의 팔꿈치가 이미지 어디에 위치하는지 나타낸다. 명백하게 이 기술은 이미지에 있는 사람이 누구인지 인식하지 못한다. 이 알고리즘은 단순하게 몸의 위치 정보를 추정할 뿐이다.
좋아, 이게 왜 흥미진진한데? 자세 추정은 다양한 쓰임세가 있다. 우리는 더 많은 개발자가 자신의 고유한 프로젝트에 자세 추정을 실험하고 적용할 수 있기를 바란다. 대부분의 자세 추정 시스템이 오픈 소스지만, 시스템 셋업 또는 카메라 같은 몇가지 특별한 설정이 필요하다. TensorFlow.js에서 PoseNet을 실행하여 웹캠이 달린 데스크탑이나 핸드폰에서 곧바로 체험해 볼 수 있다. TensorFlow.js의 PoseNet은 브라우저에서 동작하기 때문에 사용자의 컴퓨터에 어떠한 포즈 데이터도 남기지 않는다.
이 모델을 사용하는 방법에 대해서 깊게 파고들어가기전에, 이 프로젝트를 가능하게 만들어준 분들에게 감사한다. George Papandreou and Tyler Zhu, Google researchers behind the papers Towards Accurate Multi-person Pose Estimation in the Wild and PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model, and Nikhil Thorat and Daniel Smilkov, engineers on the Google Brain team behind the TensorFlow.js library.
PoseNet 시작하기
PoseNet은 싱글 포즈와 멀티플 포즈를 추측할 수 있다. 이 의미는 알고리즘의 버전에 따라서 한사람만 추정하거나 여러 사람을 추정할 수 있다는 것이다. 왜 버전이 두 개로 나뉘냐? 한사람의 포즈를 디텍트 하는 것이 더 빠르고 간단하다 그러나 이미지에 한가지의 객체만 있어야 한다. 우리는 싱글-포즈 모델을 먼저 알아볼 것이다. 왜냐하면 더 쉬우니까
고수준의 자세 추정은 두개의 페이즈로 나뉜다.
- convolutional neural network를 통해 RGB 이미지가 공급된다
- 싱글-포즈 또는 멀티-포즈 디코딩 알고리즘은 다음과 같은 것들을 모델의 아웃풋에서 해독하는데 사용횐다. pose, pose 신뢰 점수, Keypoint 위치 그리고 Keypoint 신뢰 점수
그럼 이러한 키워드가 무엇을 의미하는지 보자
- pose - 가장 높은 레벨에서 PoseNet은 키포인트의 리스트와 각각의 detect 된 사람의 인스턴스 레벨의 신뢰 점수를 포함한 pose object를 리턴한다
 PoseNet returns confidence values for each person detected as well as each pose keypoint detected. Image Credit: “Microsoft Coco: Common Objects in Context Dataset”, https://cocodataset.org.
PoseNet returns confidence values for each person detected as well as each pose keypoint detected. Image Credit: “Microsoft Coco: Common Objects in Context Dataset”, https://cocodataset.org.
-
Pose 신뢰 점수 - 이것은 자세의 추정에서 신뢰 점수 전체를 나타낸다. 이것의 범위는 0.0에서 1.0 까지이다. 이 점수는 충분한 점수를 얻지 못한 포즈를 없애는데 사용될 수 있다.
-
KeyPoint - 코, 오른쪽 귀, 왼쪽 무릎, 오른쪽 발 등등 추정된 사람 자세의 부분. PoseNet은 현재 17개의 keypoint를 디텍할 수 있다. 밑에 그 예가 있다.
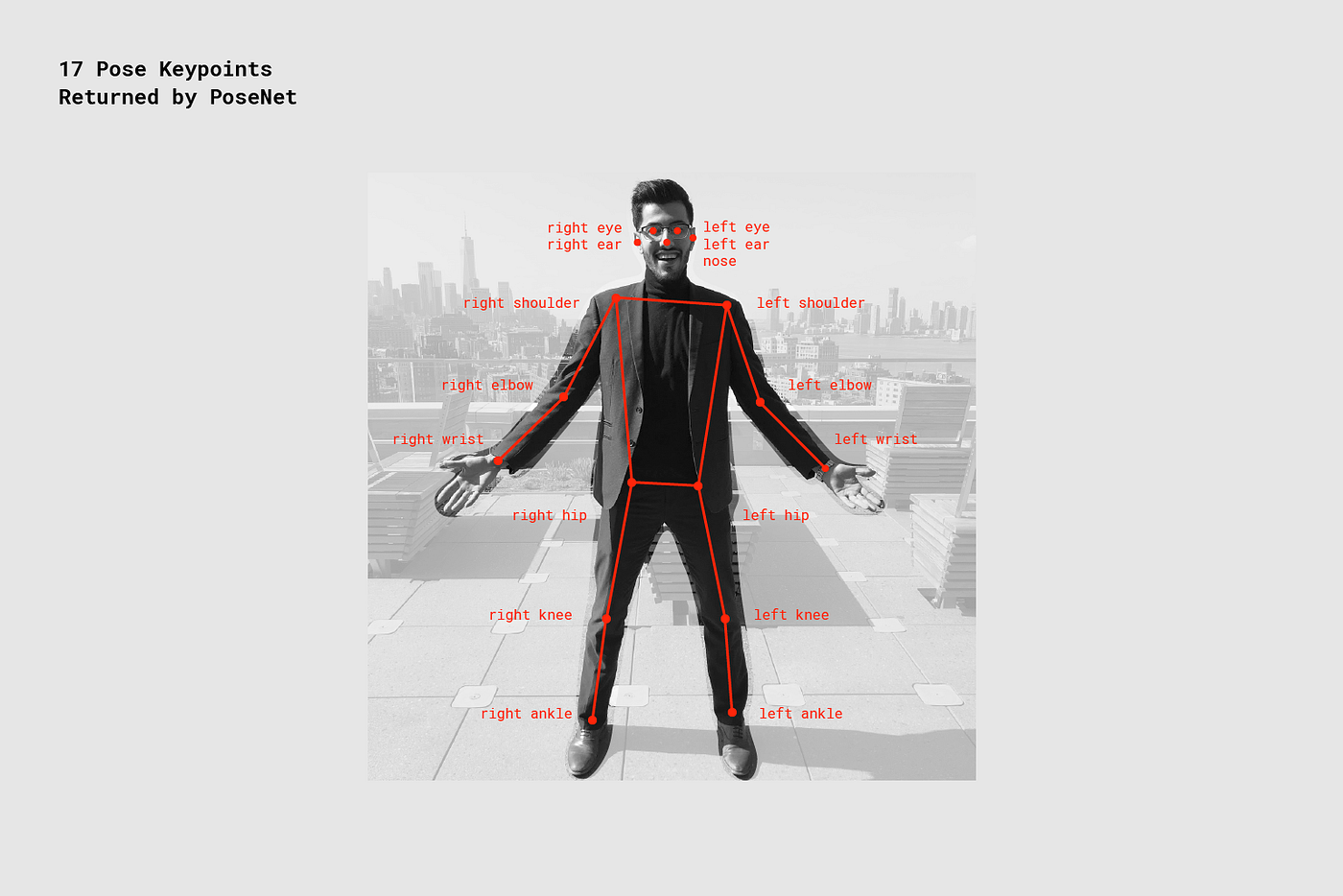
-
KeyPoint 신뢰 점수 - 이것은 추정한 keypoint 위치가 정확한지를 나타낸다. 이것의 범위는 0.0 부터 1.0 까지이다. 충분한 점수를 얻지 못한 keypoint를 지우는데 사용할 수 있다.
-
Keypoint Position - 인풋 이미지에서 키포인트가 디텍 된 x,y 좌표를 나타낸다.
Part 1: TensorFlow.js와 PoseNet 라이브러리 임포트하기
모델의 복잡성을 추상화하고 기능을 사용하기 쉬운 방법으로 캡슐화하는 많은 작업이 진행되었다. PoseNet 프로젝트 설정 방법의 기본 사항을 살펴보자.
이 라이브러리는 npm으로 설치할 수 있다
npm install @tensorflow-models/posenet
그리고 모듈을 가져온다
import * as posenet from '@tensorflow-models/posenet';
const net = await posenet.load();
또는 페이지에 껴넣는다
<html>
<body>
<!-- Load TensorFlow.js -->
<script src="https://unpkg.com/@tensorflow/tfjs"></script>
<!-- Load Posenet -->
<script src="https://unpkg.com/@tensorflow-models/posenet">
</script>
<script type="text/javascript">
posenet.load().then(function(net) {
// posenet model loaded
});
</script>
</body>
</html>
Part 2a: single-person 자세 추정
 Example single-person pose estimation algorithm applied to an image. Image Credit: “Microsoft Coco: Common Objects in Context Dataset”, https://cocodataset.org.
Example single-person pose estimation algorithm applied to an image. Image Credit: “Microsoft Coco: Common Objects in Context Dataset”, https://cocodataset.org.
시작하기 전에 single-pose 추정 알고리즘은 2개를 추정하는거보다 간단하고 쉽다. 이것은 이미지나 비디오에서 오직 한 사람만이 이미지의 중앙에 위치할 때 가장 이상적이다. 불이익은 만약 많은 사람이 이미지에 존재한다면 각각의 사람들의 키포인트가 섞여서 추정될 수 있다. 만약 많은 사람이 이미지에 등장한다면 multi-pose 추정 알고리즘을 사용해라
single-pose 추정 알고리즘의 inputs을 알아보자
-
Input image element - 자세를 추정할 이미지를 가지고 있는 html 요소이다. 보통 img나 video tag를 가지고 있다. 그리고 이미지나 비디오는 사각형 형태여야 한다.
-
Image scale factor - 0.2부터 1까지의 값을 가지고 기본값은 0.5이다. 네트워크를 통해 이미지를 공급하기 전에 이 값을 낮게 설정하면 이미지를 축소하고 정확도를 포기하여 네트워크의 속도를 높일 수 있다.
-
Flip horizontal - 기본값은 false이다. 만약 포즈를 뒤집거나 대칭시켜야 하는 경우 이 값을 true로 설정하면 된다.
-
Output stride - 32,16 또는 8이어야 하고 기본값은 16이다. 내부적으로 이 파라메터는 신경망 안에 레이어의 높이와 넓이에 영향을 준다. 고차원적인 수준에서는 이것은 정확도와 속도에 영향을 준다. 저차원적인 수준에서는 출력값이 낮을수록 속도는 빨라지지만 정확도는 낮아진다.
이제 single-pose 추정 알고리즘의 아웃풋을 알아보자.
- 포즈 신뢰 점수와 17개의 키포인트를 가진 배열
- 각 키포인트에는 키포인트 위치 및 키포인트 신뢰 점수가 포함된다.
해당 코드 블락은 single-pose 추정 알고리즘을 사용하는 방법이다.
const imageScaleFactor = 0.50;
const flipHorizontal = false;
const outputStride = 16;
const imageElement = document.getElementById('cat');
// load the posenet model
const net = await posenet.load();
const pose = await net.estimateSinglePose(imageElement, scaleFactor, flipHorizontal, outputStride);
다음과 같이 출력이 나온다
{
"score": 0.32371445304906,
"keypoints": [
{ // nose
"position": {
"x": 301.42237830162,
"y": 177.69162777066
},
"score": 0.99799561500549
},
{ // left eye
"position": {
"x": 326.05302262306,
"y": 122.9596464932
},
"score": 0.99766051769257
},
{ // right eye
"position": {
"x": 258.72196650505,
"y": 127.51624706388
},
"score": 0.99926537275314
},
...
]
}
Part 2b: Multi-person 자세 추정
 Example multi-person pose estimation algorithm applied to an image. Image Credit: “Microsoft Coco: Common Objects in Context Dataset”, https://cocodataset.org
Example multi-person pose estimation algorithm applied to an image. Image Credit: “Microsoft Coco: Common Objects in Context Dataset”, https://cocodataset.org
multi-person 자세 추정 알고리즘은 이미지에서 많은 사람과 포즈를 추정할 수 있다. 이것은 single-pose 알고리즘보다 느리지만 사진에 많은 사람들이 있는 경우 이점을 가지고 있다. 그리고 잘못된 자세를 추정하지 않을 확률이 좀 더 높다. 이런 이유로, 한사람의 자세를 디텍해야 하는 경우에도 이 알고리즘을 쓰는게 바람직 할 수도 있다.
게자다가, 이 알고리즘의 특징은 사람수에 따라서 성능이 영향을 받지 않는다는 것이다. 감지를 해야할 사람이 15명이든 5명이든 같은 계산 시간이 걸린다.
inputs을 봐보자
- Input image element - single-pose 추정과 같다
- Image scale factor - single-pose 추정과 같다
- Flip horizontal - single-pose 추정과 같다
- Output stride - single-pose 추정과 같다
- Maximum pose detections - Integer이고 기본값은 5이다. 디텍을 할 최대 포즈 개수이다.
- Pose confidence score threshold - 0.0 ~ 0.1값이고 기본값은 0.5이다. 고차원적 수준에서 이것은 반환되는 포즈의 신뢰 점수를 제어한다
- Non-maximum suppression(NMS) radius - 픽셀의 숫자이다. 고차원적 수준에서는 반환되는 포즈 사이의 최소 거리를 제어한다. 이 값의 기본값은 20이며 대부분의 경우에 괜찮다. 더 작은 정확도의 포즈를 나타내거나 숨기거나 할 때 사용될 수 있지만, 자세 신뢰 점수가 충분히 좋지 않을 때 사용하기에 좋다
출력값을 알아보자
- 자세의 배열을 내는 추정치
- 각 자세에는 single-pose 추정 알고리즘에서 설명한 것과 동일한 정보가 포함되어있다.
이 코드 블록은 multiple-person 추정 알고리즘을 사용하는 방법을 부여준다
const imageScaleFactor = 0.50;
const flipHorizontal = false;
const outputStride = 16;
// get up to 5 poses
const maxPoseDetections = 5;
// minimum confidence of the root part of a pose
const scoreThreshold = 0.5;
// minimum distance in pixels between the root parts of poses
const nmsRadius = 20;
const imageElement = document.getElementById('cat');
// load posenet
const net = await posenet.load();
const poses = await net.estimateMultiplePoses(
imageElement, imageScaleFactor, flipHorizontal, outputStride,
maxPoseDetections, scoreThreshold, nmsRadius);
출력값은 다음과 같다
// array of poses/persons
[
{ // pose #1
"score": 0.42985695206067,
"keypoints": [
{ // nose
"position": {
"x": 126.09371757507,
"y": 97.861720561981
},
"score": 0.99710708856583
},
...
]
},
{ // pose #2
"score": 0.13461434583673,
"keypositions": [
{ // nose
"position": {
"x": 116.58444058895,
"y": 99.772533416748
},
"score": 0.9978438615799
},
...
]
},
...
]
여기 까지가 PoseNet 데모를 시작하기에 충분하지만 모델 및 구현의 세부 사항이 궁금하다면 계속 읽어보자.
For Curious Minds: A Technical Deep Dive
이 섹션에서는 single-pose 추정 알고리즘에 대해 좀 더 자세히 설명한다. 고차원적 수준에서 프로세스는 다음과 같다
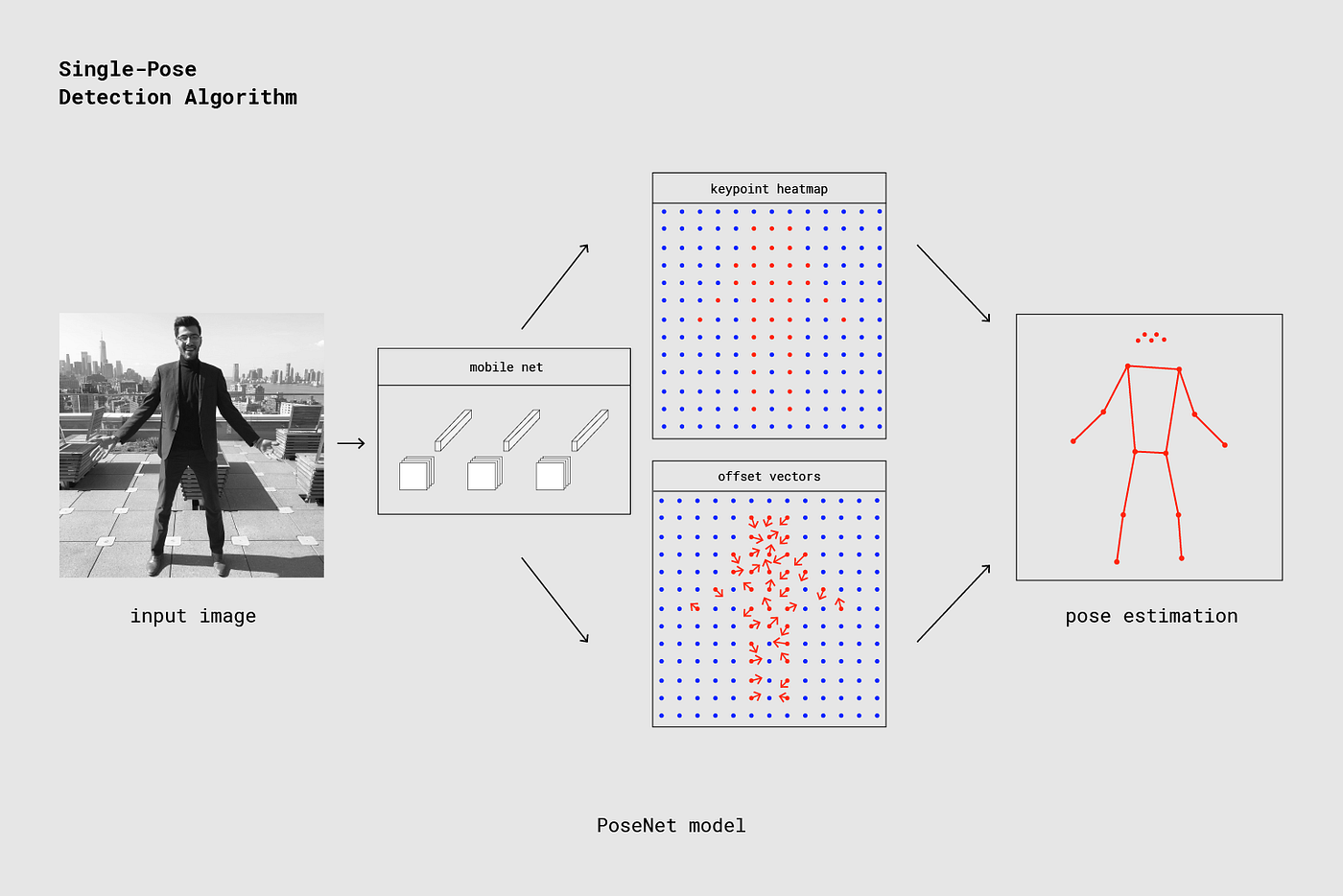 Single person pose detector pipeline using PoseNet
Single person pose detector pipeline using PoseNet
중요한 디테일은 ResNet과 MobileNet을 사용하여 PoseNet을 구성하였다는 것이다. Resnet 모델이 좀 더 높은 정확도를 가지지만 크기가 크고 많은 레이어를 가지며, 페이지의 로딩시간과 추론 시간이 실시간 어플리케이션에는 적합하지 않다. 여기서는 모바일 장치에서 실행되도록 설계된 MobileNet 모델을 사용하였다.
Revisiting the Single-pose Estimation Algorithm
Processing Model Inputs: 출력 Strides에 대한 설명
먼저 output strides에 대해 알아봐서 PoseNet 모델의 출력(주로 heatmaps and offset vectors)를 얻는 방법을 보자.
편의성을 위해, PoseNet 모델은 이미지 크기가 변하지 않는다. 이 뜻은 이미지의 축소여부에 관계없이 원본 이미지와 동일한 배율로 포즈 위치를 예측할 수 있다. 즉, 위에서 언급한 output stride를 런타임에 설정하여 성능을 낮추고 더 높은 정확도를 얻을 수 있다.
Output stride는 인풋 이미지 크기를 기준으로 출력 크기를 얼마나 줄일지 결정한다. 이 인자는 모델 출력과 레이어의 크기에 영향을 미친다. 만약 output stride를 높인다면 네트워크안에 레이어와 출력의 해상도가 낮아지고 그에 따라 정확도도 낮아진다. 이 구현에서 output stride는 8,16 또는 32의 값을 가질 수 있다. 다른 말로 32의 값을 가진 output stride는 가장 빠른 퍼포먼스를 보여주지만 낮은 정확도를 보여줄 것이고, 8의 경우 높은 정확도와 낮은 속도를 보여줄 것이다. 우리는 16을 추천한다.
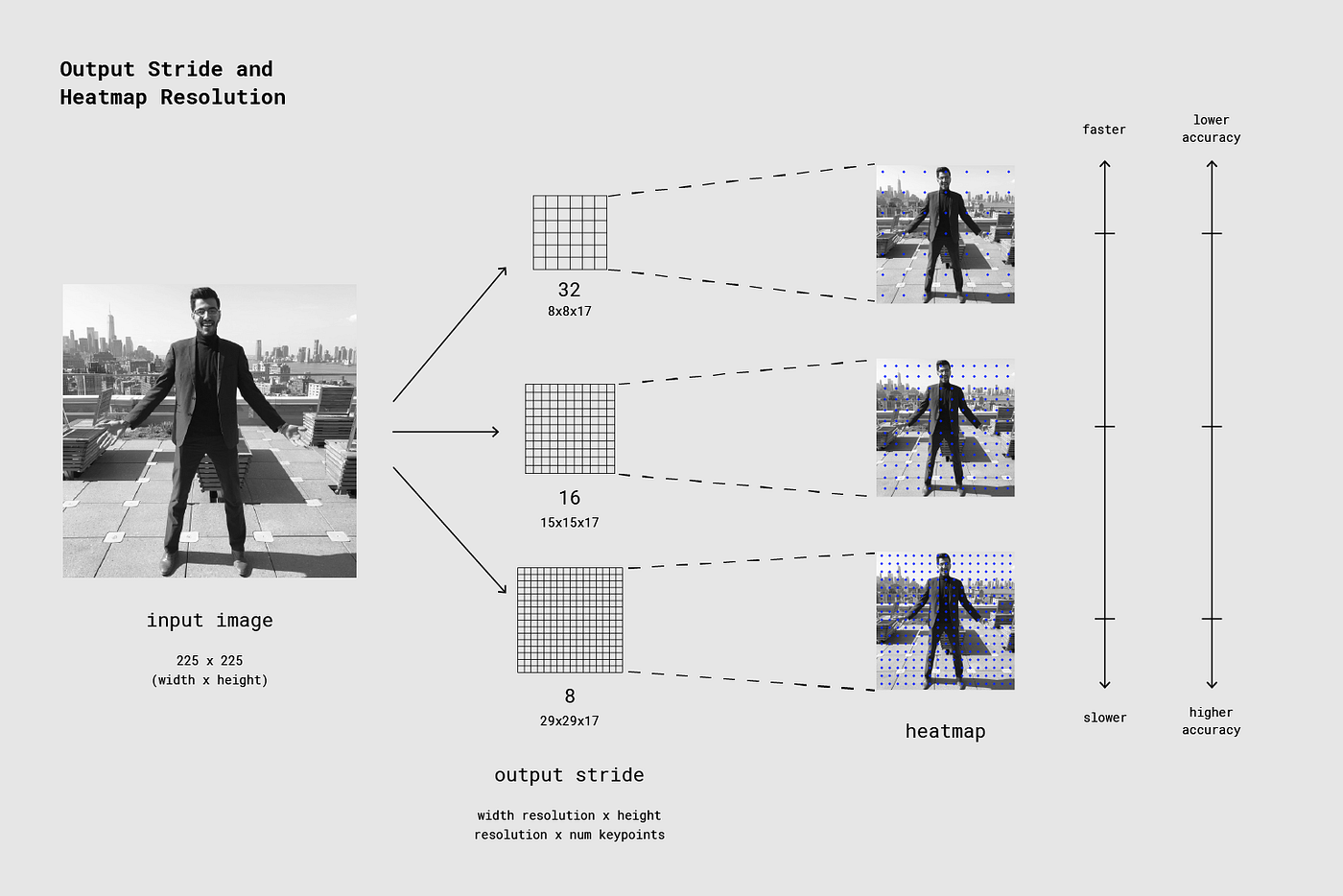 The output stride determines how much we’re scaling down the output relative to the input image size. A higher output stride is faster but results in lower accuracy.
The output stride determines how much we’re scaling down the output relative to the input image size. A higher output stride is faster but results in lower accuracy.
Model Outputs: Heatmaps and Offset Vectors
PoseNet이 이미지를 처리할 때 리턴되는 값은 자세 키포인트와 대응되는 이미지의 가장 높은 신뢰 영역을 발견하기 위한 offset vector과 이를 포함한 heatmap이다.
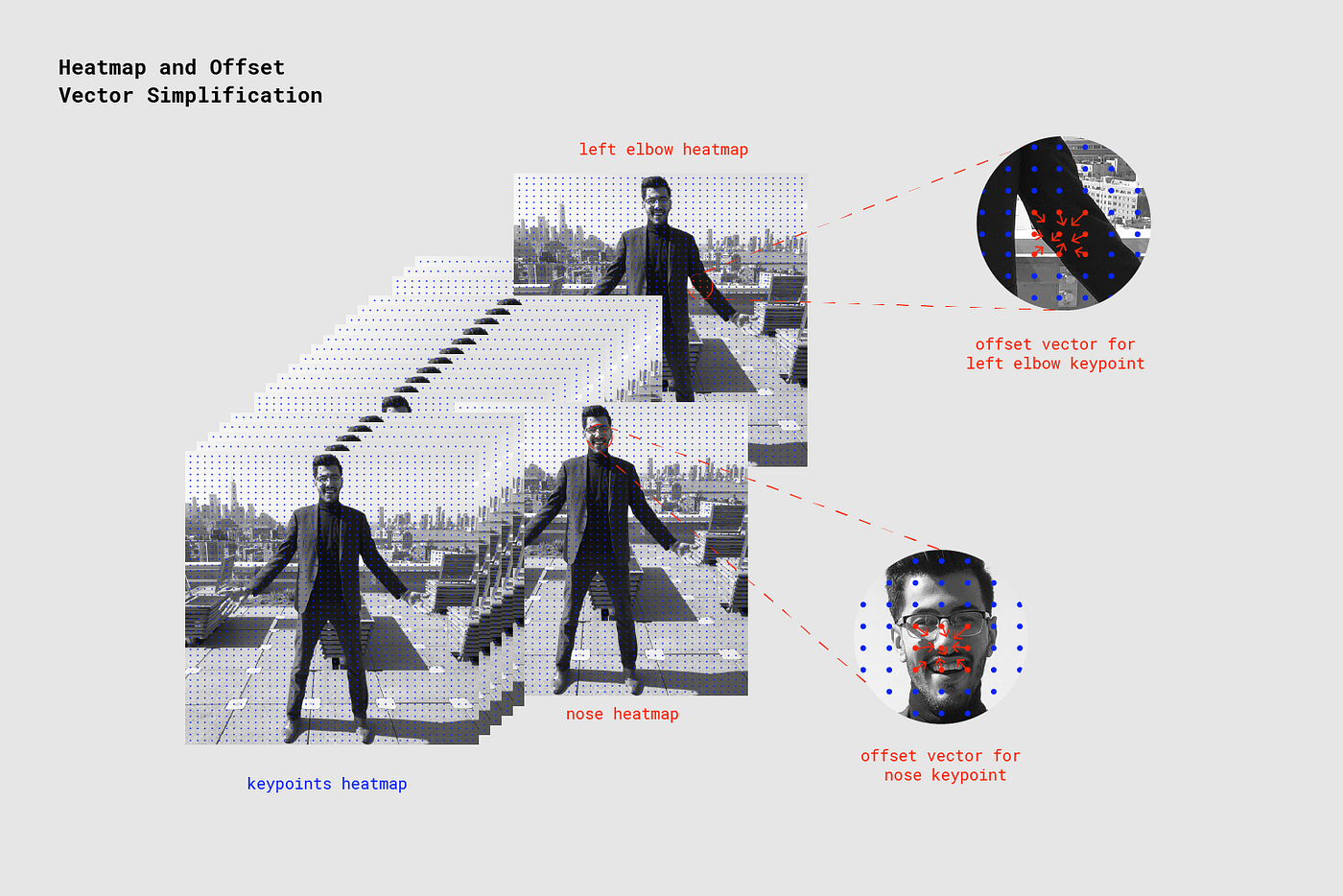 Each of the 17 pose keypoints returned by PoseNet is associated to one heatmap tensor and one offset vector tensor used to determine the exact location of the keypoint.
Each of the 17 pose keypoints returned by PoseNet is associated to one heatmap tensor and one offset vector tensor used to determine the exact location of the keypoint.
이 출력쌍은 해상도라고 언급되는 높이와 너비를 포함한 3D tensor이다. 해상도는 아래의 공식에 따라 입력 이미지 크기와 output stride에 의해 결정된다.
Resolution = ((InputImageSize - 1) / OutputStride) + 1
// Example: an input image with a width of 225 pixels and an output
// stride of 16 results in an output resolution of 15
// 15 = ((225 - 1) / 16) + 1
Heatmaps
각각의 히트맵은 해상도 * 해상도 * 17의 3D 텐서이다. 17은 PoseNet에서 디텍한 키포인트의 개수이다. 예를들언 이미지 크기가 225이고 output stride가 16이면 151517이 될 것이다. 각각의 3번째 차원(17)은 특정한 키포인트와 대응된다. 히트맵의 각각의 포지션은 신뢰 점수를 가지고, 이것은 해당 히트맵 포인트에서 벡터를 따라 이동할 때 키포인트의 정확한 위치를 예측하는데 사용된다.
Offset Vectors
각각의 offset vector는 해상도해상도34의 3D Tensor이다. 34는 키포인트 * 2를 의미한다. 이미지 크기가 225이고 output stride가 16이면 이것은, 151534가 될 것이다. 히트맵은 키포인트가 어디 위치하는지를 나타내는 근사치이고 offset vectors는 히트맵 포인트에 해당하며 해당 히트 맵 포인트에서 벡터를 따라 이동할 때 키포인트의 정확한 위치를 예측하는데 사용된다.
모델의 출력으로 부터의 포즈 추정
이미지가 모델을 통해 공급된 후 몇가지 계산을 수행하여 출력에서 포즈를 추정합니다. 예를 들어, 단일 포즈 추정 알고리즘은 각각 자체 신뢰 점수 및 x, y 위치를 갖는 키포인트 (부품 ID로 색인화 됨)의 배열을 포함하는 포즈 신뢰 점수를 반환합니다.
포즈의 키포인트를 얻는 방법
-
sigmoid 활성화는 점수를 얻을 수 있는 히트맵에서 수행된다 scores = heatmap.sigmoid()
-
argmax2d는 각각의 부위에서 가장 높은 점수를 가진 히트맵의 x y 인덱스를 얻기 위하여 키포인트 신뢰 점수에 대해 수행된다. 이는 본질적으로 부위가 존재할 가능성이 가장 높은 곳입니다. 이렇게하면 크기가 17*2인 텐서가 생성되며 각 행은 각 부위의 점수가 가장 높은 y,x 인덱스 값입니다. heatmapPositions = scores.argmax(y, x)
-
각 부품 의 오프셋 벡터 는 해당 부품에 대한 히트 맵의 x 및 y 색인에 해당하는 오프셋에서 x 및 y를 가져 와서 검색됩니다. 그러면 크기가 17x2 인 텐서가 생성되며 각 행은 해당 키포인트의 오프셋 벡터입니다. 예를 들어, 인덱스 k의 부품에서 히트 맵 위치가 y 및 d 인 경우 오프셋 벡터는 다음과 같습니다. offsetVector = [offsets.get(y, x, k), offsets.get(y, x, 17 + k)]
-
키포인트를 얻기 위해 각 부위의 히트맵 x와 y에 output stride를 곱한다음 해당 오프셋 벡터에 추가한다 keypointPositions = heatmapPositions * outputStride + offsetVectors
-
마지막으로 각각의 키포인트 신뢰 점수는 히트맵 위치의 신뢰 점수이다. 포즈 신뢰 점수는 키포인트의 점수의 평균이다.